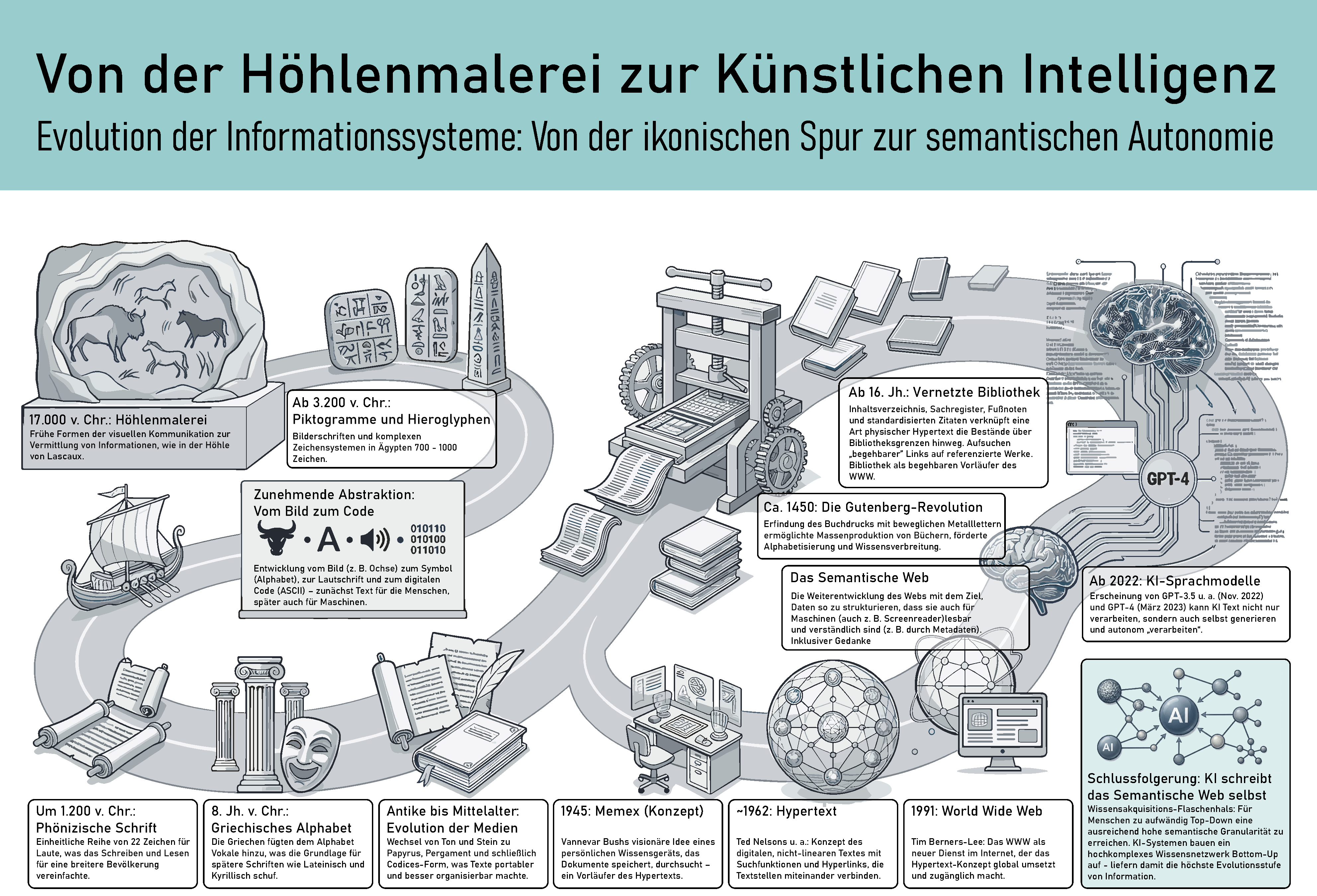
Schrift ist nicht nur ein Symbolsystem, sondern ein Vehikel für Kultur‑ und Wissensspeicherung. Von paläolithischen Höhlenbildern bis hin zu heutigen KI‑Modellen erstreckt sich eine medienhistorische Entwicklung, die zunehmend abstrakte und maschinenlesbare Codes hervorbrachte. Die auf dem beigefügten Poster visualisierte Zeitleiste weist drei Themenstränge aus: (1) die allmähliche Reduktion der Zeichenvarianz bei gleichzeitig wachsender semantischer Leistungsfähigkeit, (2) die Verschiebung von analogen zu digitalen Darstellungsformen und (3) die Demokratisierung von Textzugang durch technische Innovationen. Dieser Artikel folgt dieser Entwicklung, ergänzt sie um wissenschaftliche Quellen und verortet sie medienphilosophisch.
„KI schreibt das Semantic Web selbst, indem sie Daten nicht nur strukturiert, sondern semantisch interpretiert."
Die ältesten „Texte" waren nicht aus Buchstaben, sondern aus Bildern: In europäischen und afrikanischen Höhlen der Altsteinzeit (z. B. Lascaux oder Chauvet) wurden Tierdarstellungen und Handabdrücke gefunden. Forscher*innen der MIT‑Harvard‑Universität interpretieren diese Höhlenbilder als kommunikative Akte: Sie wurden an akustischen „Hotspots" angebracht, die den Klang verstärkten, und könnten so frühe sprachliche Fähigkeiten begleiten [1]. Eine MIT‑Studie betont zudem, dass Sequenzen von Punkten und Linien in eiszeitlichen Höhlen als proto‑schriftliche Zeichen zur Erfassung von Tierverhalten fungierten.
Später entwickelten Hochkulturen differenzierte Bildschriften. Die Sumerer verwendeten Piktogramme für konkrete Objekte und entwickelten daraus die Keilschrift, bei der Keile mittels Rohrstiften in Ton gedrückt wurden. Diese Zeichen repräsentierten zunächst Wörter oder Silben und später auch Laute; der Bestand bewegt sich je nach Periode zwischen über 1.000 Zeichen in der archaischen Frühschrift und rund 600 im akkadisch-altbabylonischen Standardrepertoire (Schmandt-Besserat, 1992) [2]. In Ägypten entstanden um 3 200 v. Chr. Hieroglyphen, die Bildzeichen, Silbenzeichen und Konsonanten kombinierten. Der Bestand schwankt je nach Periode zwischen rund 700 Zeichen im klassischen Mittelägyptisch und über 5.000 in der Spätzeit (Allen, 2014). In China wurden in der Shang‑Dynastie (ca. 1 300–1 050 v. Chr.) Orakelknochen mit Fragen beschriftet; die erhaltenen 200 000 Fragmente gelten als älteste chinesische Schriftstücke.

Die Entwicklung von Lautschriften reduzierte die Anzahl benötigter Zeichen drastisch und machte Schrift lernbarer. Das phönizische Alphabet (um 1200 v. Chr.) war ein reines Konsonantenalphabet. Das griechische Alphabet fügte im 8. Jahrhundert v. Chr. Vokale hinzu und ermöglichte damit eine genauere Wiedergabe der gesprochenen Sprache. Es wurde zur Grundlage des lateinischen und kyrillischen Alphabets. Alphabetische Schrift reduzierte den Zeichensatz auf wenige Dutzend Symbole und erleichterte das Erlernen von Lesen und Schreiben; dadurch verbreitete sich das Konzept alphabetischer Schrift weltweit.
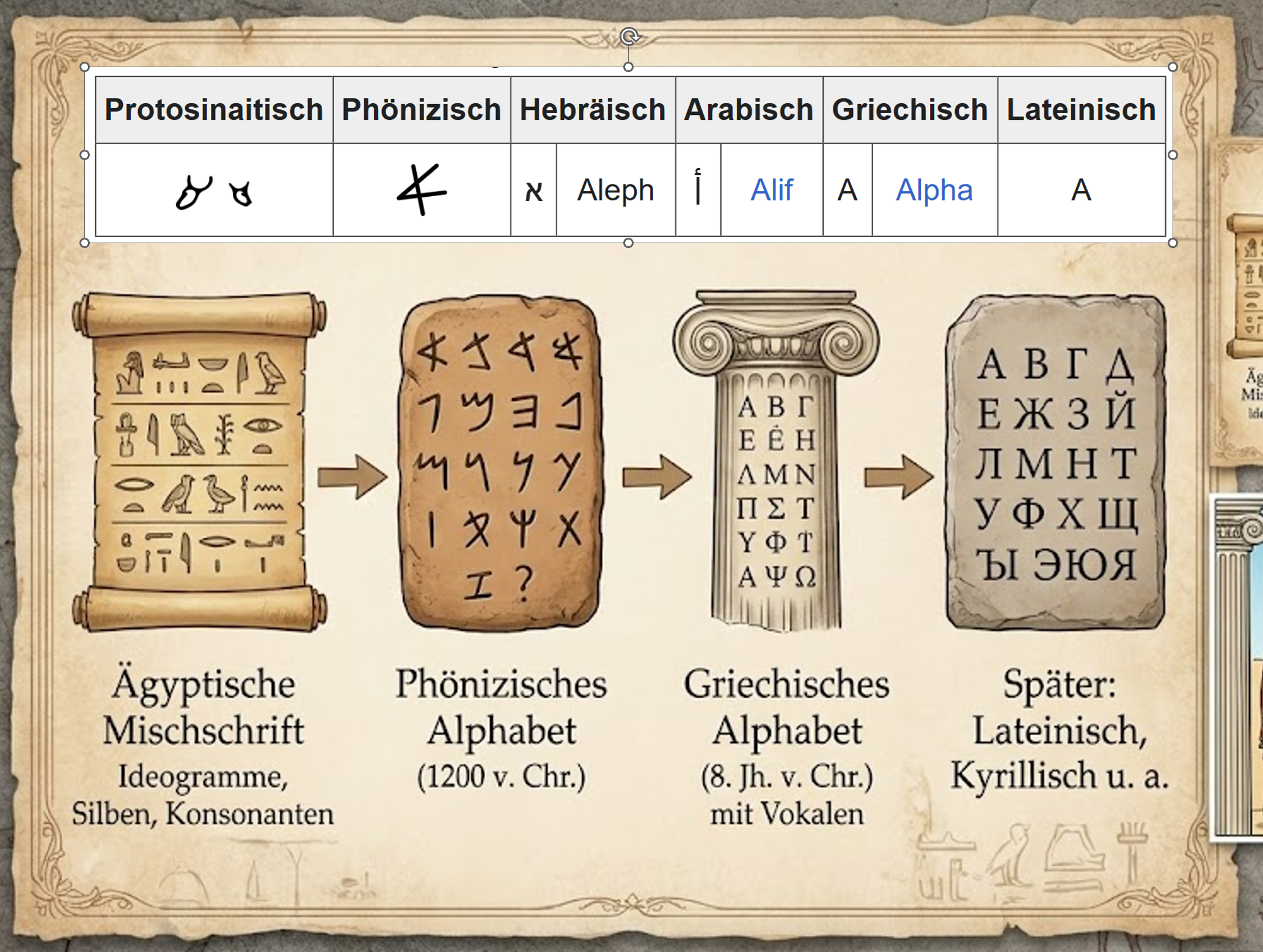
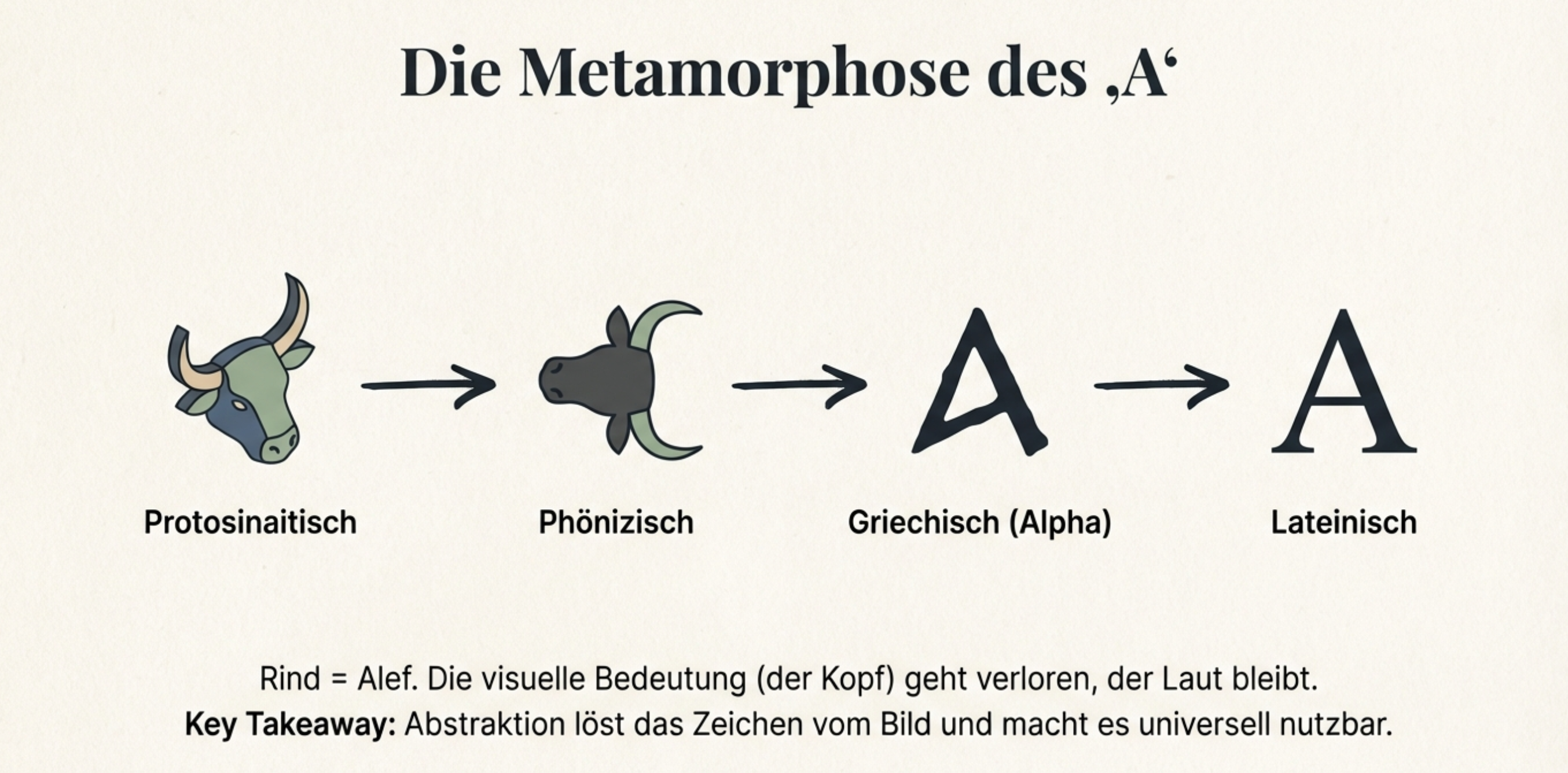
Die Form des Buchstabens „A" illustriert den Prozess der Abstraktion. In der phönizischen Periode hieß der Buchstabe wie im Hebräischen aleph, was „Ochse" bedeutet; sein Zeichen leitete sich von einem stilisierten Ochsenkopf ab und wurde von den Griechen als Alpha übernommen [3]. Der lateinische Großbuchstabe A entwickelte sich später aus dieser Form [3]. Die Reduktion komplexer Bildzeichen zu abstrakten Lautsymbolen ist im Poster auf einer rechten „Abstraktionspyramide" visualisiert und wird in Abschnitt 8 vertieft.
Parallel zur symbolischen Entwicklung veränderten sich die Speichermedien. Ton‑ und Steintafeln waren dauerhaft, aber schwer und unhandlich. Ab etwa 2400 v. Chr. produzierte man in Ägypten Papyrusrollen – zehn bis vierzig Meter lange Schriftbahnen mit Etiketten am Ende für Titel. Pergament aus Tierhaut (ab 3. Jh. v. Chr.) war haltbarer und beidseitig beschreibbar, allerdings teurer. In römischer Zeit löste der Codex (eine gebundene Blattform) die Rolle ab und erleichterte das Blättern und Einbinden von Inhaltsverzeichnissen.

Die Erfindung des Buchdrucks im 15. Jahrhundert markiert einen Wendepunkt. Johannes Gutenberg kombinierte bewegliche Metalllettern, ölbasierte Tinte und eine Presse zur gleichmäßigen Druckverteilung. Ab 1455 konnte dadurch die Gutenberg‑Bibel als eines der ersten Druckwerke hergestellt werden, was die kostengünstige Massenproduktion identischer Bücher ermöglichte. Die Verbreitung des Buchdrucks steigerte die Alphabetisierung und beschleunigte die Wissensverbreitung; sie bildete damit die Grundlage für wissenschaftliche Revolutionen und demokratisierte Bildung. Gleichzeitig entstanden Tabellen, Inhaltsverzeichnisse und alphabetische Register; die Standardisierung von Seitenzahlen ermöglichte verlässliche Verweise und bildete die Basis moderner Informationssysteme.

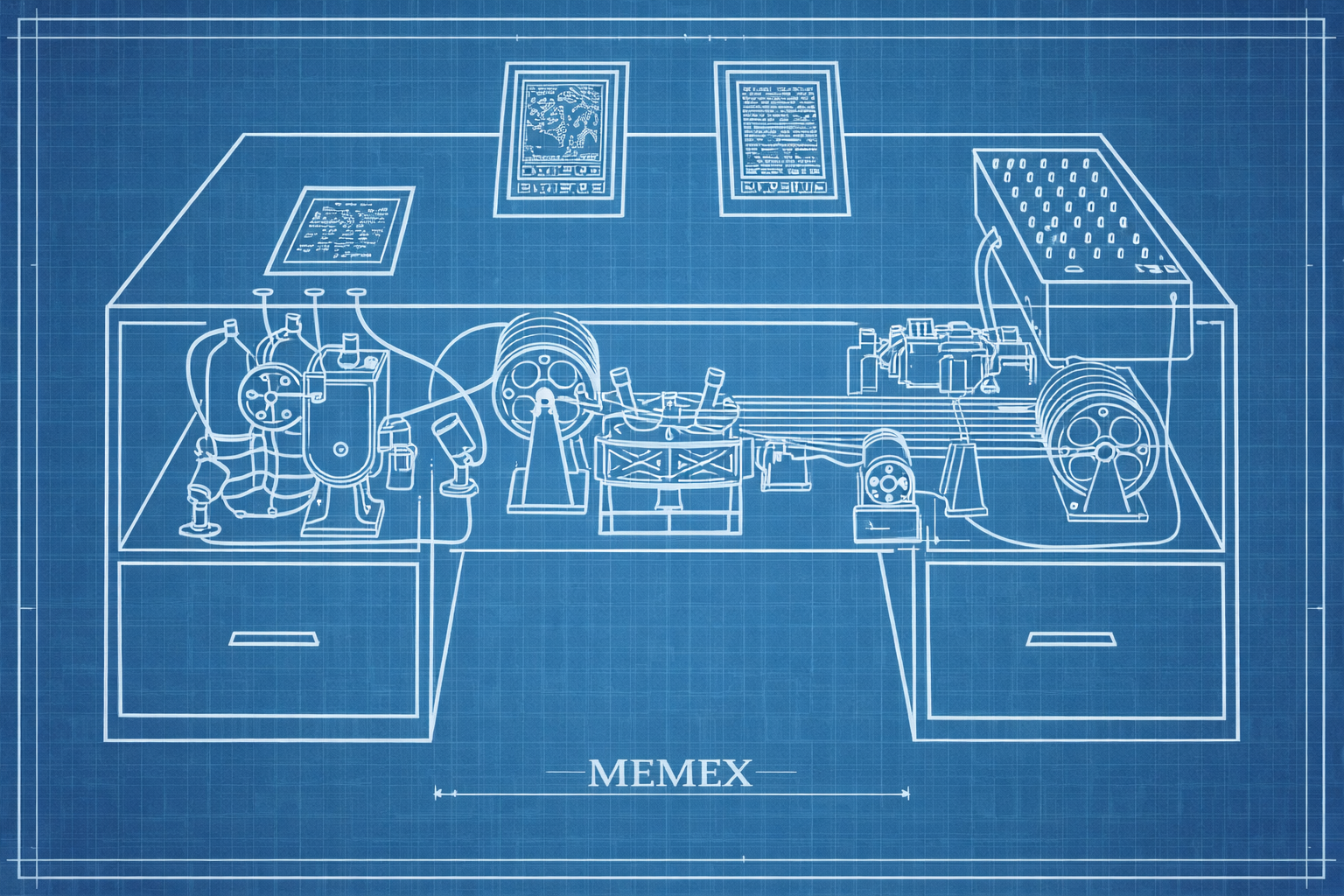
Bereits 1945 entwarf Vannevar Bush mit dem „Memex" ein Gerät, das Dokumente auf Mikrofilm speichert und über assoziative Pfade verknüpft [4]. Ted Nelson prägte 1963 den Begriff Hypertext und entwickelte im Projekt Xanadu ein System vernetzter Dokumente [5]. Douglas Engelbart demonstrierte 1968 im „Mother of All Demos" ein NLS‑System mit Hypertextverknüpfungen, Maus, Mehrfenster‑Anzeige und Video‑Telekonferenz [6]. Diese visionären Konzepte legten die Grundlagen für die digitale Vernetzung von Text.
Tim Berners‑Lee erweiterte diese Ideen, indem er 1989/90 am CERN das World Wide Web entwickelte. Dieses System verband Dokumente global über Hypertext‑Links; mit HTML, URLs und HTTP wurden Texte in einem dezentralen Netzwerk zugänglich. Die erste Website ging 1990 online, 1993 wurde das Web öffentlich freigegeben – ein Ereignis, das die Informationslandschaft grundlegend veränderte [7]. Das Web verwandelte Texte in verlinkte Informationsräume und machte Wissen breit verfügbar.

Die Semantic‑Web‑Initiative des W3C verfolgt das Ziel, Daten im Web mit maschinenlesbarer Bedeutung zu versehen. Sie stellt eine gemeinsame Grundlage bereit, die es ermöglicht, Daten aus verschiedenen Anwendungen und Gemeinschaften zu teilen und wiederzuverwenden (Berners-Lee, Hendler & Lassila, 2001) [8]. Durch Standards wie das Resource Description Framework (RDF) und Ontologien können Beziehungen zwischen Dingen beschrieben und Informationen aus unterschiedlichen Quellen verknüpft werden. Obwohl diese Vision nur teilweise umgesetzt wurde (z. B. in Wikidata und Linked Open Data), bildete sie die theoretische Basis für Wissensgraphen.
Seit 2020 definieren Large Language Models (LLMs) eine neue Phase der Textevolution. LLMs basieren auf neuronalen Transformer‑Architekturen und werden mit gewaltigen Textcorpora trainiert. Sie können Muster der Sprache erlernen, Texte generieren und Fragen beantworten. GPT‑3 (2020) verfügte über 175 Milliarden Parameter und zeigte beeindruckende Leistungen bei Übersetzung, Fragebeantwortung und Generierung von Nachrichtenartikeln [9]. Die Popularität solcher Modelle stieg 2022/23 rapide: ChatGPT erreichte innerhalb von zwei Monaten nach seiner Einführung 100 Millionen monatliche Nutzer*innen [10] und überschritt 2024 die Marke von 200 Millionen Besuchen. Neue Generationen wie GPT‑4 erlauben die multimodale Verarbeitung von Text und Bild.
Die großen Sprachmodelle nähern sich den Zielen des Semantic Web auf unerwartete Weise. Sie können heterogene Wissensquellen integrieren, Zusammenhänge herstellen und durch Retrieval‑Augmented Generation aktuelles Wissen einbeziehen. Obwohl sie mit Herausforderungen wie Verzerrungen und Halluzinationen kämpfen (Bender et al., 2021), eröffnen sie neue Formen von Informationssystemen: Texte werden nicht nur gespeichert, sondern „verstanden" und kreativ weiterverarbeitet.

Die Transformation von Bild zu Code ist eine zentrale Dynamik der Textevolution. Wie im Poster dargestellt, veranschaulicht ein vereinfachter Ochsenkopf (proto‑semitisches Zeichen) den Übergang vom Bildsymbol zum Buchstaben „A" und weiter zum Binärcode. In protophoenizischen, phönizischen, hebräischen, arabischen, griechischen und lateinischen Schriften blieb der Bezug auf den Ochsen (Aleph) erhalten, wurde aber grafisch und phonetisch abstrakter. Mit Flusser (1987) lässt sich diese Bewegung als kategorialer Übergang von ikonischer zu diskreter Codierung verstehen: Schrift übersetzt Welt nicht mehr ins Bild, sondern in lineare Zeichenketten. Durch diese Abstraktion können wenige Zeichen vielfältige Bedeutungen tragen und von breiten Bevölkerungsgruppen erlernt werden.

Mit der Elektronisierung der Schrift wurde die Symbolreduzierung radikalisiert. ASCII (American Standard Code for Information Interchange) kodiert ursprünglich 128 Zeichen in 7‑bit‑Binary‑Codes; heute wird zur Kompatibilität ein 8‑bit‑Byte genutzt [11]. Jedes Zeichen – Buchstaben, Ziffern oder Steuerzeichen – erhält einen eindeutigen binären Wert. Diese minimale Zeichenvarianz ermöglicht universelle maschinelle Verarbeitung bei maximaler algorithmischer Dichte. Die zunehmende Formalisierung schafft die Grundlage für maschinelles Lesen, Übersetzen und Generieren von Text.
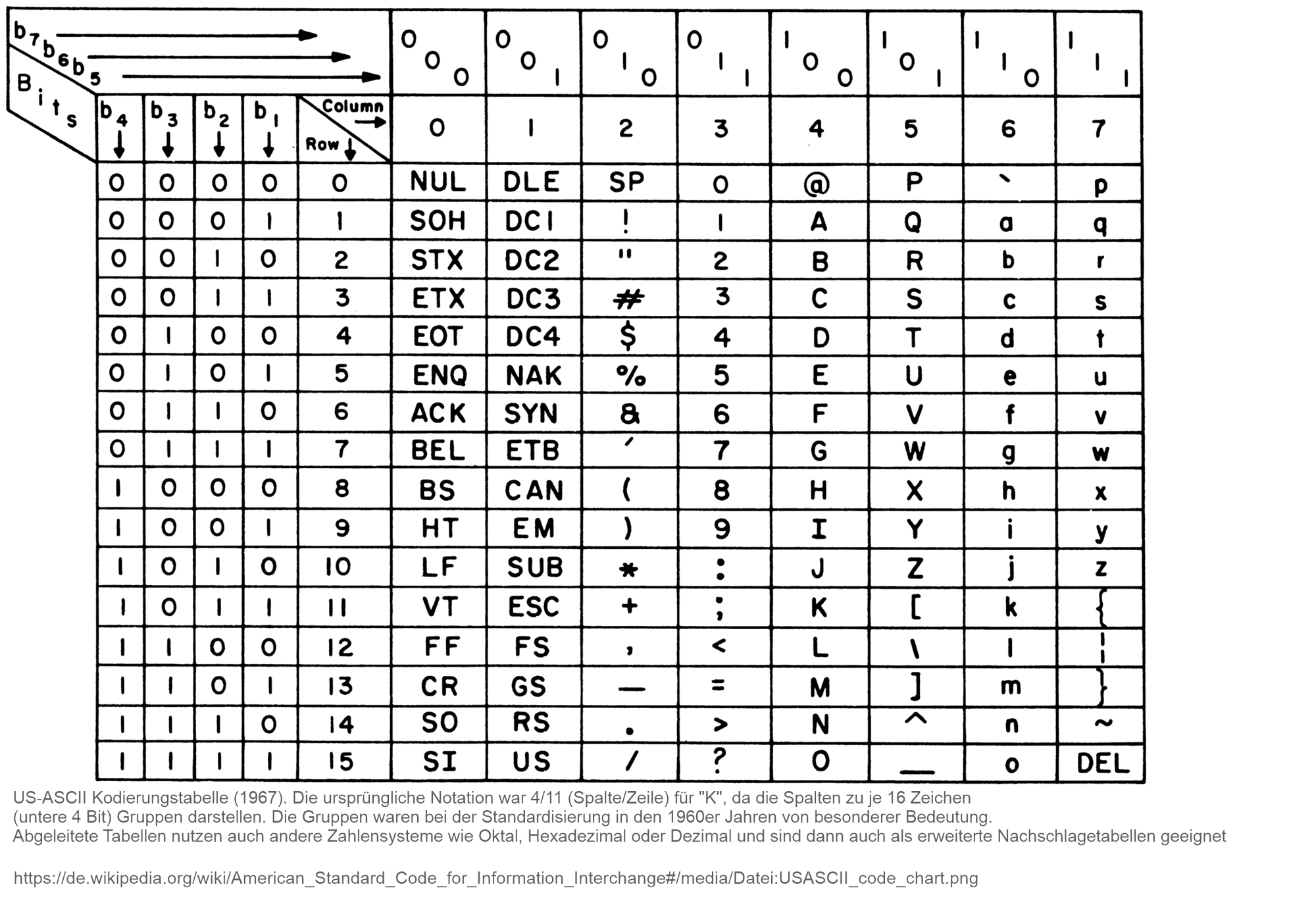
Die maschinenlesbare Schrift bildet die Basis für generative KI. LLMs nutzen digitale Codierungen und statistische Modelle, um aus Wortsequenzen Wahrscheinlichkeitsräume und semantische Vektoren zu berechnen. Dadurch wird Text zu einer dynamischen Funktion, die kontextabhängig erzeugt und angepasst werden kann. Dies entspricht der im Poster skizzierten Schlussfolgerung: KI schreibt das Semantic Web selbst, indem sie Daten nicht nur strukturiert, sondern semantisch interpretiert.

Die zunehmende Maschinenlesbarkeit eröffnet nicht nur algorithmische, sondern auch gesellschaftliche Potenziale. Web‑Zugänglichkeit bedeutet, dass Menschen mit Behinderungen Websites gleichberechtigt wahrnehmen, verstehen, navigieren und nutzen können [12]. Viele Anforderungen zur Barrierefreiheit betreffen die technische Codierung: Screenreader lesen Inhalte vor, Screen‑Magnifier vergrößern sie, und Spracherkennungssoftware ermöglicht Texteingabe [12]. Solche Lösungen profitieren von standardisierten, strukturierten Daten.
Künstliche Intelligenz verstärkt diese inklusiven Möglichkeiten. Laut einem Beitrag von Every Learner Everywhere (April 2025) sind bereits viele Assistive‑Technologien wie Screenreader, Spracherkennung und Navigationstools mit AI ausgerüstet, um Genauigkeit, Effizienz und Personalisierung zu verbessern [13]. KI‑gestützte Werkzeuge passen sich an Nutzer*innen an und bieten personalisierte Lernumgebungen, etwa durch augmentative Kommunikationsgeräte, automatische Transkriptionen oder Zusammenfassungen [13]. Für Menschen mit Lern‑ oder Konzentrationsschwierigkeiten können generative Modelle Texte in vereinfachter Form wiedergeben und gliedern. Der W3C betont, dass Barrierefreiheitsanforderungen nicht nur Menschen mit Behinderungen zugutekommen, sondern allen Nutzenden – z. B. bei schlechtem Kontrast, mobilem Zugriff oder geringen Sprachkenntnissen [12]. Damit wird Maschinenlesbarkeit zu einer Voraussetzung demokratischer Informationsverfügbarkeit und Inklusion — anschlussfähig an Habermas’ (1992) Diskurstheorie, in der zugängliche Kommunikation Bedingung legitimer Öffentlichkeit ist.
Die Evolution des Textes ist eine Geschichte der Abstraktion, Formalisierung und Demokratisierung. Von frühen Höhlenbildern über Piktogramme, Keilschrift, Alphabete und den Buchdruck bis hin zu digitalen Hypertexten zeigt sich ein kontinuierlicher Trend zur Reduktion des Zeicheninventars und zur Zunahme der semantischen Leistungsfähigkeit. Die technische Transformation – vom Papyrusrollenkodex über das Web zum binären Code – hat Texte stets nicht nur speicherbar, sondern auch zugänglicher gemacht. Hypertext vernetzte Dokumente global; das Semantic Web strebte strukturierte Daten an; große Sprachmodelle vollziehen nun eine qualitative Verschiebung, indem sie aus Texten semantische Modelle berechnen.
Die Maschinenlesbarkeit, die im Poster als Grundlage für algorithmische Semantik identifiziert wird, ermöglicht zugleich eine neue Dimension der Inklusion: Erst durch standardisierte, digitale Codes können assistive Systeme Texte für Menschen mit unterschiedlichen Fähigkeiten transformieren. Trotz ethischer Herausforderungen eröffnet diese Entwicklung die Perspektive einer breiteren gesellschaftlichen Teilhabe an Wissen. Mit Stiegler (1998) lässt sich jede dieser Stufen als „tertiäre Retention" lesen — als externe Gedächtnistechnik, die menschliche Zeit- und Sinnerfahrung mitkonstituiert. Systemtheoretisch gewendet erweitert sich mit KI-Systemen die Anschlussfähigkeit von Kommunikation (Luhmann, 1997): Sie produzieren Anschlusstexte ohne intentionale Bedeutung, aber mit funktionaler Sinnkontinuität. Die Geschichte des Textes ist somit nicht abgeschlossen – sie geht im Zeitalter der Künstlichen Intelligenz in eine Phase über, in der Informationen nicht nur gespeichert, sondern aktiv interpretiert, erzeugt und inklusiv zugänglich gemacht werden.

| Epoche | Zeichenvarianz | Form | Verarbeitbarkeit |
|---|---|---|---|
| Ikonisch (Höhlenmalerei) | ∞ kontinuierlich | Analoge Bilder | Kontextabhängige Interpretation |
| Symbolisch (Hieroglyphen) | 700 – 5.000 | Ägyptische / Sumerische Zeichen | Kulturell erlernbar |
| Phonetisch (Phönizisch) | 20 – 30 | Konsonantenalphabet | Regelbasiert dekodierbar |
| Alphabetisch (Latein / Griech.) | 24 – 26 | Voll ausgebautes Alphabet | Standardisierbar, breit erlernbar |
| Digital / Binär (ASCII) | 2 | 0 / 1 — Bitfolgen | Maschinell operationalisierbar |
| KI / LLMs (ab 2020) | emergent | Probabilistische Vektorräume | Semantisch generativ |
Literaturverzeichnis
https://news.mit.edu/2018/humans-speak-through-cave-art-0221
https://www.worldhistory.org/cuneiform/
https://www.britannica.com/topic/A-letter
https://www.theatlantic.com/magazine/archive/1945/07/as-we-may-think/303881/
https://www.computinghistory.org.uk/det/6984/Theodore-H-(Ted)-Nelson-coins-the-word-Hypertext/
https://www.opb.org/article/2023/12/09/mother-of-all-demos-oregon-1968-computer-demonstration-douglas-engelbart/
https://home.cern/science/computing/birth-web
https://www.w3.org/RDF/FAQ
https://developer.nvidia.com/blog/openai-presents-gpt-3-a-175-billion-parameters-language-model/
https://www.reuters.com/technology/chatgpt-sets-record-fastest-growing-user-base-analyst-note-2023-02-01/
https://www.techtarget.com/whatis/definition/ASCII-American-Standard-Code-for-Information-Interchange
https://www.w3.org/WAI/fundamentals/accessibility-usability-inclusion/
https://www.everylearnereverywhere.org/blog/how-ai-in-assistive-technology-supports-students-and-educators-with-disabilities/
Vollständiges Literaturverzeichnis (APA 7)
Allen, J. P. (2014). Middle Egyptian: An Introduction to the Language and Culture of Hieroglyphs (3rd ed.). Cambridge University Press. https://www.cambridge.org/core/books/middle-egyptian/
Awati, R., & Loshin, P. (2025). ASCII (American Standard Code for Information Interchange). TechTarget WhatIs. https://www.techtarget.com/whatis/definition/ASCII-American-Standard-Code-for-Information-Interchange
Bender, E. M., Gebru, T., McMillan‑Major, A., & Shmitchell, S. (2021). On the dangers of stochastic parrots: Can language models be too big? In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency (FAccT '21, S. 610–623). Association for Computing Machinery. https://doi.org/10.1145/3442188.3445922
Berners‑Lee, T., Hendler, J., & Lassila, O. (2001). The Semantic Web. Scientific American, 284(5), 34–43.
Bush, V. (1945). As we may think. The Atlantic. https://www.theatlantic.com/magazine/archive/1945/07/as-we-may-think/303881/
CERN. (n.d.). The birth of the Web. CERN. https://home.cern/science/computing/birth-web
Centre for Computing History. (n.d.). Hypertext—Ted Nelson. Centre for Computing History. https://www.computinghistory.org.uk/det/6984/Theodore-H-(Ted)-Nelson-coins-the-word-Hypertext/
Chu, J. (2018). Humans speak through cave art. MIT News. https://news.mit.edu/2018/humans-speak-through-cave-art-0221
Encyclopaedia Britannica. (n.d.-a). A (letter). In Encyclopaedia Britannica. Abgerufen am 1. März 2026. https://www.britannica.com/topic/A-letter
Encyclopaedia Britannica. (n.d.-c). Hieroglyphic writing. In Encyclopaedia Britannica. Abgerufen am 1. März 2026. https://www.britannica.com/topic/hieroglyphic-writing
Encyclopaedia Britannica. (n.d.-d). Johannes Gutenberg. In Encyclopaedia Britannica. Abgerufen am 1. März 2026. https://www.britannica.com/biography/Johannes-Gutenberg
Every Learner Everywhere. (2025). How AI in assistive technology supports students and educators with disabilities. https://www.everylearnereverywhere.org/blog/how-ai-in-assistive-technology-supports-students-and-educators-with-disabilities/
Flusser, V. (1987). Die Schrift: Hat Schreiben Zukunft? Immatrix Publications. (Neuauflage 2002 bei European Photography.)
Habermas, J. (1992). Faktizität und Geltung: Beiträge zur Diskurstheorie des Rechts und des demokratischen Rechtsstaats. Suhrkamp.
Luhmann, N. (1997). Die Gesellschaft der Gesellschaft. Suhrkamp.
Mark, J. J. (2022). Cuneiform. World History Encyclopedia. https://www.worldhistory.org/cuneiform/
Mark, J. J. (2023). Greek alphabet. World History Encyclopedia.
NVIDIA. (2021). OpenAI presents GPT-3, a 175 billion parameters language model. NVIDIA Technical Blog. https://developer.nvidia.com/blog/openai-presents-gpt-3-a-175-billion-parameters-language-model/
Oregon Public Broadcasting. (n.d.). The mother of all demos. OPB. https://www.opb.org/article/2023/12/09/mother-of-all-demos-oregon-1968-computer-demonstration-douglas-engelbart/
Reuters. (2023). ChatGPT sets record for fastest-growing user base. Reuters. https://www.reuters.com/technology/chatgpt-sets-record-fastest-growing-user-base-analyst-note-2023-02-01/
Schmandt-Besserat, D. (1992). Before writing: From counting to cuneiform. University of Texas Press.
Stiegler, B. (1998). Technics and Time, 1: The Fault of Epimetheus. Stanford University Press.
World Wide Web Consortium. (n.d.-a). Semantic Web. W3C. https://www.w3.org/RDF/FAQ
World Wide Web Consortium. (n.d.-b). Accessibility, usability, and inclusion. W3C WAI. https://www.w3.org/WAI/fundamentals/accessibility-usability-inclusion/
Bildnachweis
Alle Abbildungen: Thomas Schroffenegger, z. T. unter Verwendung von OpenAI ChatGPT und Google Gemini.